

星星之火,能否燎原?讯飞星火认知大模型测试
讯飞星火认知大模型测试
前几天科大讯飞开始了星火认知大模型的内测申请,我第一时间提交了申请,今天就收到了申请通过的消息。目前看来讯飞应该是国内最快开放的大语言模型了(百度的到现在还没给通过,阿里的还在小规模测试)。下面就来看看这个模型到底怎么样吧。
下面我将使用星火认知大模型和 ChatGPT-3.5、ChatGLM-6B 进行对比测试。这里主要测试了三个能力:写代码能力、文章生成能力和翻译能力。下面是测试的过程:
注:由于我电脑显存只有 6GB,所以这里使用的 ChatGLM-6B 是经过 int4 量化的模型,实际表现不代表 ChatGLM 的完整能力
文章生成能力 & 翻译能力
首先测试的是文章生成能力,这里用一个之前的例子来做测试:给 AI 一个单词列表,让他使用列表中的单词来写一篇英文文章,并且给出这篇文章的翻译。使用该方法可以同时测试模型的文章生成能力和翻译能力。以下是测试结果:
1. 星火认知大模型

星火大模型在我还没有给出单词列表的时候就自己生成了一个单词列表,并且按照我的提示生成了文章和翻译,生成的文章中确实包含了单词列表中所有的单词,给出的翻译也大体上没有问题。但是这毕竟是自己生成的单词列表,我们要测试的是给他指定的单词列表来生成文章的能力。


在给出指定的单词列表后,星火大模型生成了一篇文章,但是并没有给出翻译,经过一次提示后才给出了中文翻译。给出的中文翻译大体意思没有问题,但有个别的单词翻译有一些小瑕疵。
为了评估生成文章的能力,我这里使用了一个作文批改的 AI 来评估生成的内容:

然后又使用了一个 Python 程序来判断生成的文章中使用了多少单词:

所以最终星火认知大模型生成的文章获得了 94 分的高分,但是只使用了 6 个列表中的单词。
2. ChatGPT

ChatGPT 这边完美理解了我的指令,并且一次性生成了英文文章和中文翻译。但因为token的限制,中间被打断了一次,不过在提示 “继续” 后补全了内容。ChatGPT 的翻译十分流畅,但是有丢词语的现象出现。


另外,ChatGPT 生成的文章也获得了98分的高分,并且在生成的文章中使用了16个单词。
3. ChatGML-6B(int4量化)


ChatGLM 这边由于我显存的问题,生成文章之后就显存溢出,无法继续生成翻译,所以只能再让他重新翻译一遍文章:

可以看到,ChatGLM 给出的翻译意思大体正确,但是有个别的单词存在翻译错误。
评估一下生成的文章的质量;


可以看到,ChatGLM 生成的文章也有95分的高分,但是仅用到了2个列表中的单词。
写代码能力
对于写代码能力测试,这里使用了一个特别简单的例子,让 AI 用 Python 写一个统计文章中包含多少列表中单词的小程序,下面是测试结果:
1. 星火认知大模型

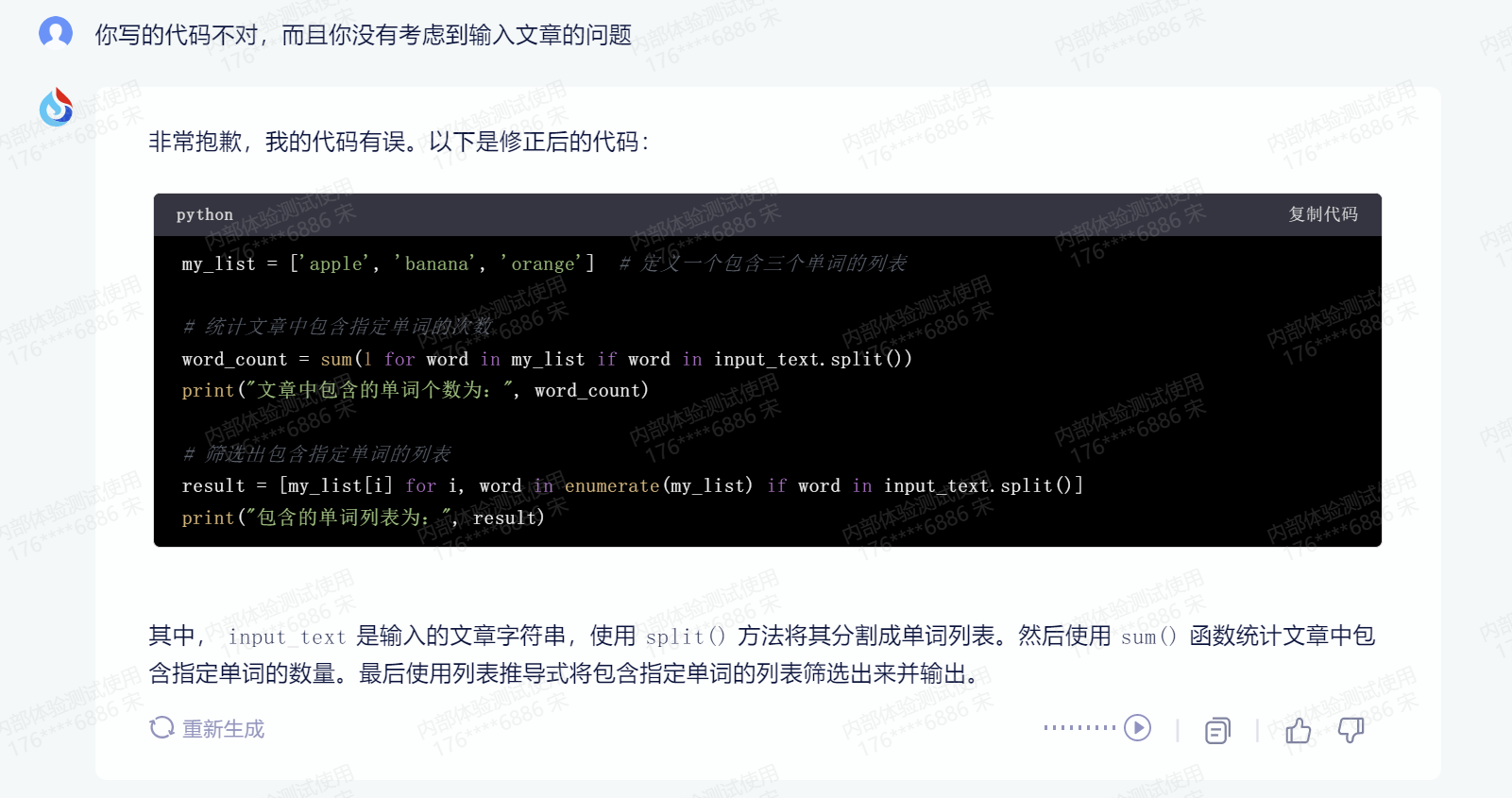
可以看到星火大模型好像并没有理解我的问题,写出的代码和要求基本没有关系,无法正常运行。并且在指出问题后仍然没能改正。
2. ChatGPT

可以看到 ChatGPT 理解了我的要求,并且写出了正确的代码,实测可以正常运行,我们还可以更近一步,让 ChatGPT 改进这段代码:

可以看到,我提示ChatGPT要考虑大小写的问题,ChatGPT正确理解了我的意思,并且修改了代码,实现了我所需要的功能,实测这段代码完美符合要求,可以正常运行。
3. ChatGLM(int4量化)

ChatGLM 理解了我的意思,写出了一段看着还有模有样的代码,但也是无法正常运行,仔细看会发现存在不少问题。
总结
通过上面的对比可以看到,目前国内的大模型和 ChatGPT 有一定的差距,即使是国产的模型,对于中文的理解能力也仍然有待提高。不过,目前可以看到各个大厂都加入到了大模型的开发中。星星之火,可以燎原。相信后续可以看到国产大语言模型能够有所突破,期待国产大模型百花齐放的那一天。
-
感谢你赐予我前进的力量
-
 微信
微信 -
 支付宝
支付宝


