

使用 ChatGPT 辅助背单词
提高工作效率,解放生产力,ChatGPT 还能这么用?
一个月前,发现我的OpenAI的点数要过期了,这么好的东西当然不能浪费,应该用 OpenAI 的接口做一些东西,进过一番思索,就有了用ChatGPT生成语境法背单词语料的想法。

作为一名学生,背单词已经成为了日常,但是目前主流的背单词方式都只是针对独立的单词,背完单词如果不加以应用很快就会忘记,所以我想到可以用 ChatGPT 来给单词生成一段故事,这样就可以加深对于单词的记忆。
有了想法,下面开始实践。
我们首先打开ChatGPT,输入我们的需求,ChatGPT就会给出实现的代码。

好了,以上就是我实现这个项目的全部过程,我们下期再见。
显然这是不可能的,上面的代码根本无法达到我们所需的效果。现在 ChatGPT 虽然足够强大,但也远没有达到上述的地步。目前这类的大语言模型只是一个很好的辅助工具,合理的利用可以大大提升我们的学习和工作的效率。
下面我将和大家分享我用 ChatGPT 辅助实现批量生成语境法背单词的语料的方法。
首先,单词列表是生成文章的基础,我们需要收集整理要背诵的单词列表。正好之前我做高考大纲词汇词频分析的时候收集了不少单词列表,这里就直接拿来用了。我将这些数据都整理成了csv格式,方便后续在 Python 中进行操作。
接下来就是调用 ChatGPT 的 API 来实现自动生成语料,这种简单的项目用 Python 来实现是最方便的,下面开始实践。
首先,需要写一个调用 OpenAI 的 ChatGPT 的 API 来生成英文文章的函数。这里如果我们直接向ChatGPT 寻求帮助,写出来的代码并不可用。因为这是新的API,ChatGPT 并不清楚调用方法。好在OpenAI 的官方文档写的十分详细,直接参考官方文档(Chat completion - OpenAI API)就可以轻松完成。
接下来就是对数据进行处理。这里可以直接让 ChatGPT 写一段 Python 代码,将 csv 表格的数据整理成 Python 列表,方便后续在 Python 中进行操作。
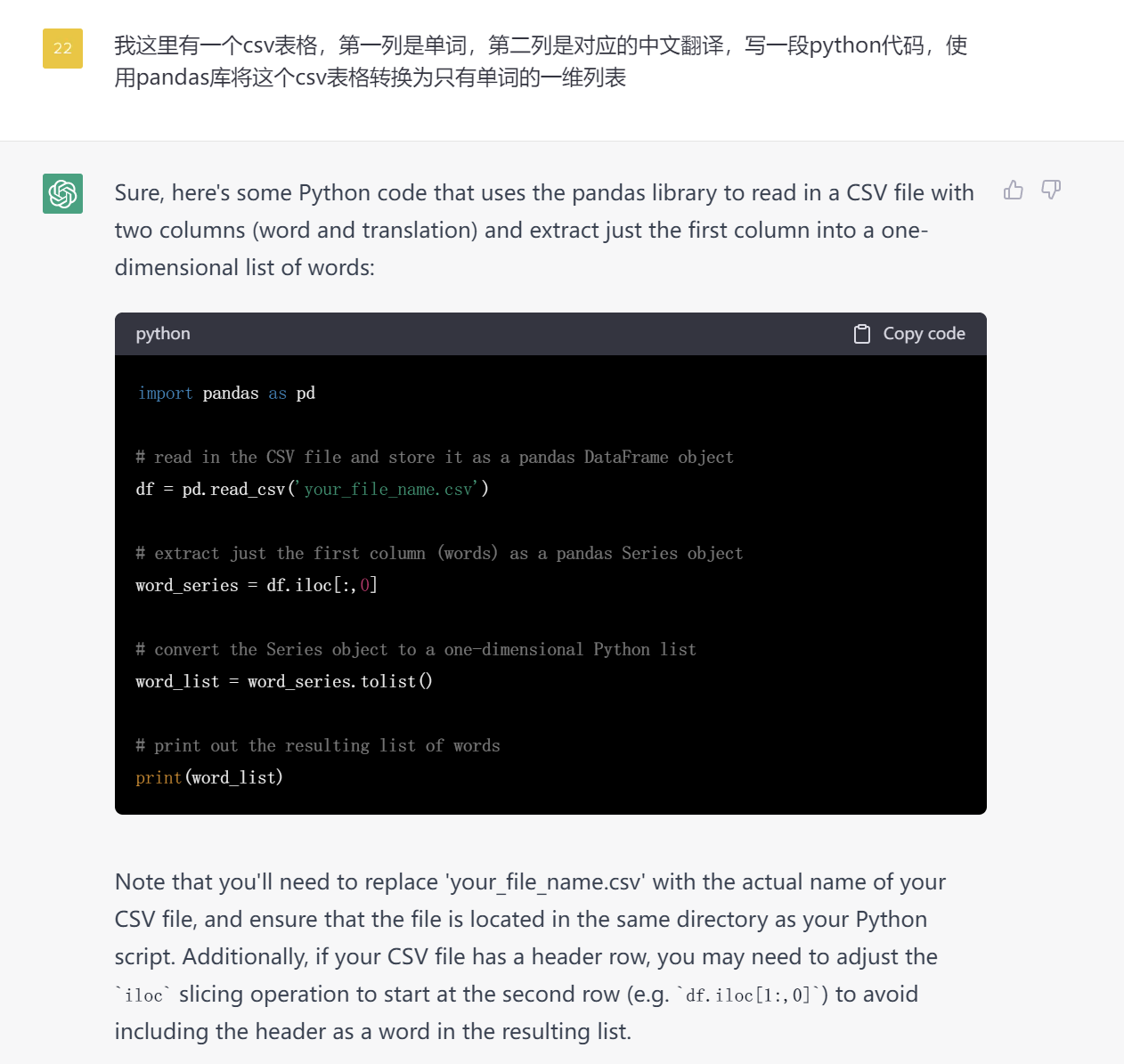
运行这段代码测试一下,报错了,因为我的csv文件使用的是GBK编码,而这里默认使用UTF-8来解码。

尽管我知道报错的原因,但还是将这段报错交给了ChatGPT,试试看他能不能解决这个问题。

从他的回答中可以看出他理解了这个报错的原因,也给出了解决方案,但是他并没有考虑到正确的编码是GBK,这里还是需要结合个人经验来判断。
接下来就是使用单词列表中的单词生成语料,这里直接将需求交给ChatGPT。这里的描述一定要讲清楚需求,不然生成的代码会有问题。

这段代码还存在一个问题,他将所有不在生成的文本中的单词都添加到了列表的最后,这样操作会打乱之前的词频排序,所以还需要让ChatGPT来修复一下这个问题。

可以看到ChatGPT成功修复了这个问题,并且还提醒我,如果生成的文章中反复缺少某些词,这种方法可能会导致某些词被多次使用。那么我们就让他按照自己的思路来修改代码。

然而ChatGPT好像并没有理解自己的意思,这段代码和上面的建议没有太多的关系。不过我们现在已经有了思路,按照这个思路在之前的代码上稍加修改,便得到了最终的代码:
1 | # 获取单词的翻译 |
1 | # 主函数 |
我这里重构了 generate_article() 函数,将生成的文章直接保存为Markdown文件,并且返回未使用的单词。在 generate_articles_from_word_list() 函数中也做了对应的修改,将返回的未使用的单词加入到下一次生成的单词列表的开头。这样保证了既不丢失单词,又不破坏词频的顺序。
当然,这段代码还有不少可以优化的地方,比如查找单词时加入查找单词的变形;一个单词如果尝试多次都无法生成文章,直接舍弃这个单词等等。
现在,我们已经通过一个单词列表生成了一堆 Markdown 格式的文章。为了便于阅读和打印,我们接下来需要将这些文章合并为一个PDF文件。

依然是使用 ChatGPT 生成代码,稍作修改,即可完成 Markdown 文件到 PDF 的转换。
另外,在转换时发现之前忘记给单词列表添加空格来换行,恰好这时候 OpenAI 发布了GPT4,而且 New Bing 使用的就是 GPT4,这里正好拿来做个测试。

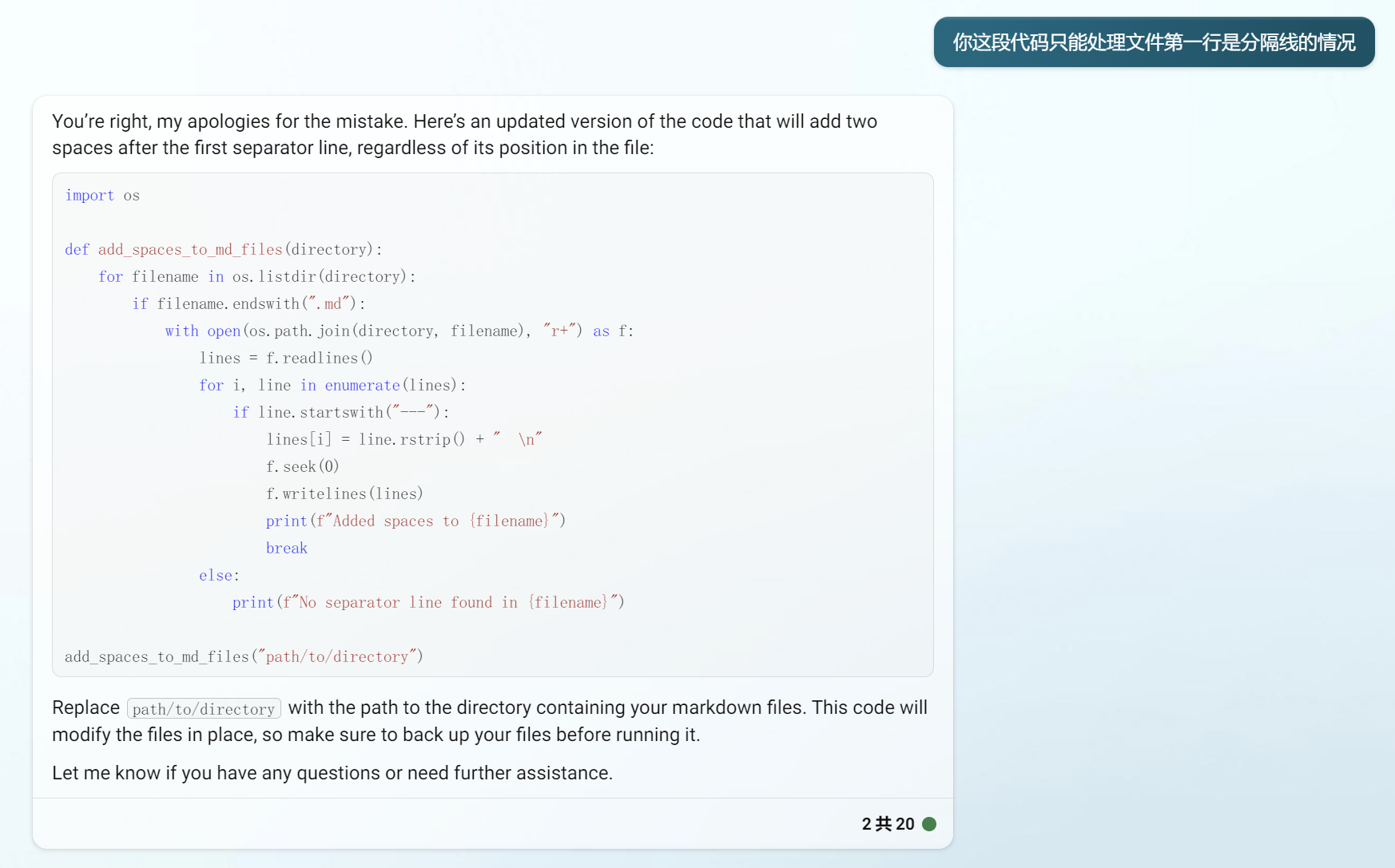

看起来 New Bing 的 GPT4 相比 3.5 没有特别大的提升(这里指基于 GPT4 的 New Bing 和 ChatGPT 3.5,ChatGPT4 没有测试,不做讨论),一个需求仍然需要多次的指正才能达到预期的效果。
所以,现在 AI 水平仍然无法完全取代人类的工作。AI 不能让一个从来没有写过代码的人写出可用的代码,也不能代替人类产生新的想法。不过 AI 确实可以提升我们的工作效率。我作为一名普通的学生,只用了几个小时,就完成了以往可能是数名英语老师数周的工作量。
截止写稿时,OpenAI 已经发布了GPT 4,完整版的 GPT4 能力有了进一步的提升,并且拥有了视觉能力,近几年AI的进步速度让人叹为观止,我一年前的想象如今已经变成现实。现在已经可以看到强人工智能的雏形,AGI 已经不再是天方夜谭。
但无论如何,我们都要保持终身学习的态度,只有不断的学习新的知识,接收新生事物,才能跟上时代的步伐。
-
感谢你赐予我前进的力量
-
 微信
微信 -
 支付宝
支付宝


